Data
A Datasource provides access to data. It continuously listens and stores changes to maintain a consistent data index.
What is a datasource?
Internally, a datasource is composed of (see image below):
- A storage service: provides access to the data and can be accessed by any tool that communicates using Amazon S3 protocol.
- An index service: stores the data state and stands as the only source of truth for request on data state.
- A synchronizer: maintains the storage and the index database synchronized.
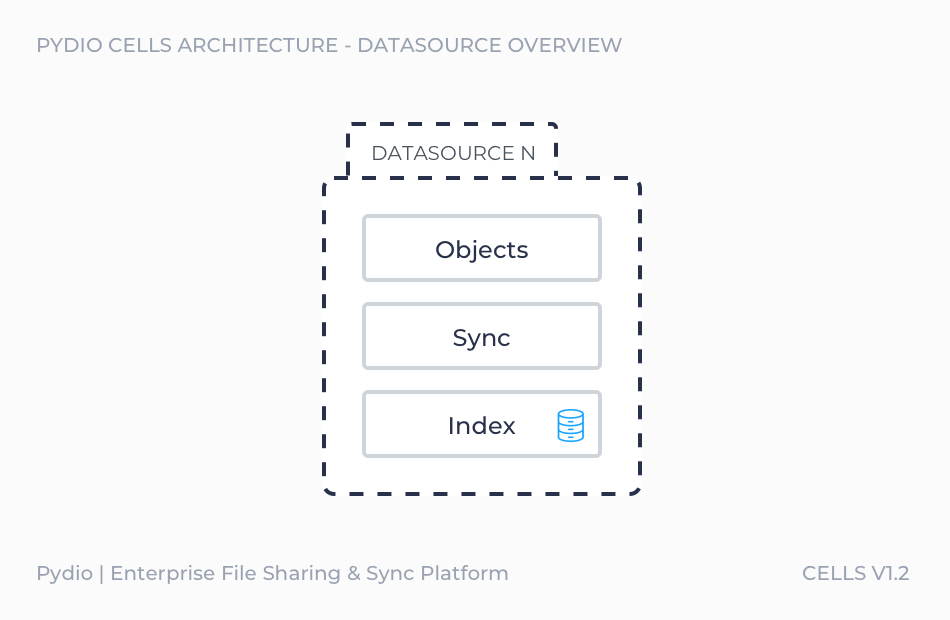
Every time a datasource has its state updated, the index service publishes events to notify the other services.
Below are the name pattern of the corresponding services, each of them is always started as a fork:
pydio.grpc.data.index.<service_id>pydio.grpc.data.object.<service_id>pydio.grpc.data.sync.<service_id>
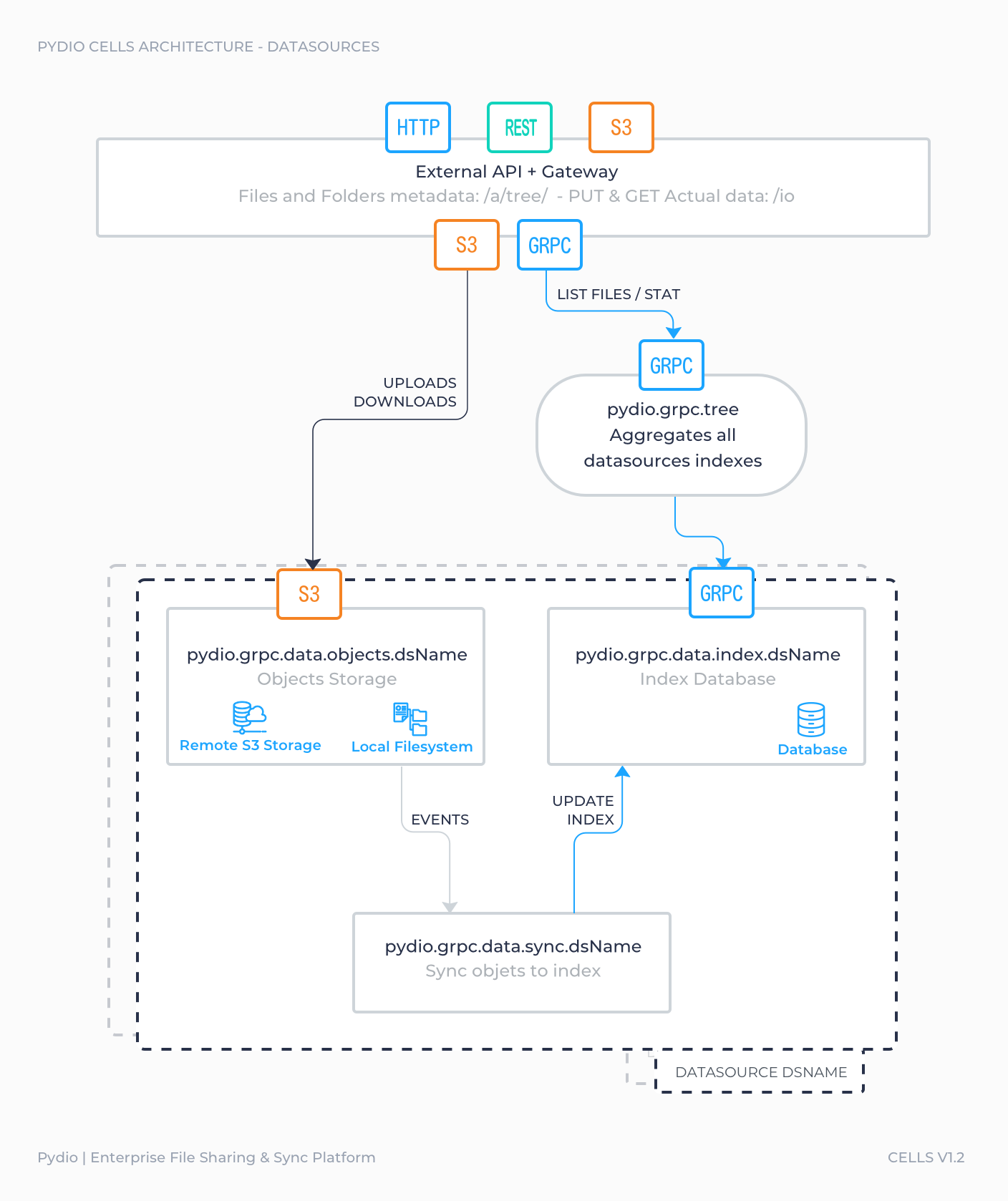
Each datasource index is stored in 3 independent tables of the default database. It can be configured to use any other database. This eases the sharding of data across multiple nodes.
You should also note that the object service, that is implemented by a fork of minio might be mutualised between more than one datatsource. Typically, all datasources that exposes a local file system which root folder resides in the same parent directory share a single object service.
The tree service
The tree service aggregates all datasources and presents the whole as a single data tree in which each datasource is a child of the root node.
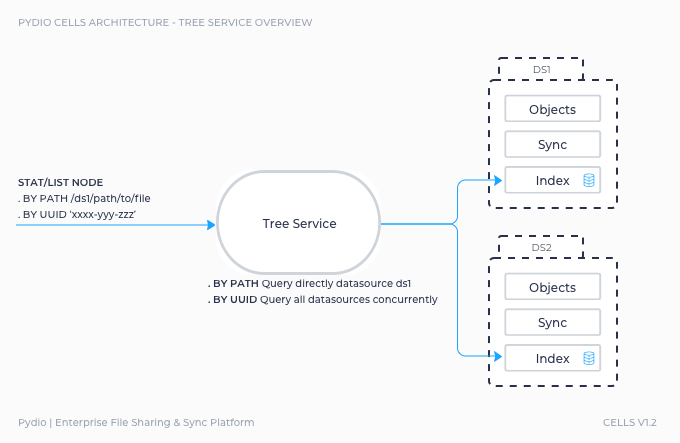
This master tree is used internally to identify nodes by their UUID. It is used globally inside the application, and the ACL (Access Control List) are just flags positioned on any node UUID to grant read/write access to a user to a given node. This is how workspaces and shares are implemented. See previous chapter to learn more about Identity Management.
Back to top