Parallelism and Concurrency
Parallelism
Various use cases may lead to one action of a job being started multiple times "in parallel":
- An event-based job received many events at once
- A QUERY is configured to select multiple objects and trigger one action for each object
- Multiple actions are chained to the output of an action
This powerful feature can make use of parallelism to e.g. perform tasks on all the available CPUs and speed up the processes. But it can have an important drawback: running tons of tasks in parallel may quickly result in overloading your server CPU!.
Limiting Concurrency
To avoid that issue, jobs define a "Max. Parallel Tasks" parameter that you define to tell the internal queue to never run more than XX action instances at the same time.
Example
Let's have a look at the internal job used for extracting images thumbnails and exif metadata:
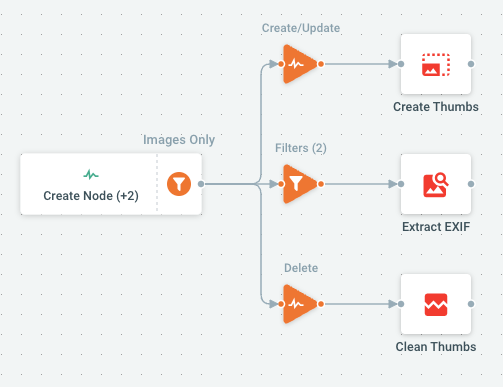
Now imagine that a user is uploading 1000 JPG images to Cells at once.
- Input trigger could eventually receive 1000 "Create Node" events in a very short period of time
- For all these images both "Create Thumbs" and "Extract EXIF" will be launched in parallel. These actions require reading the entire file and manipulating image pixels, and are CPU-heavy.
Without any restrictions, you could end up having Cells processing 2000 heavy-load actions concurrently! If you notice the Max. Parallel Tasks: 5 value, we avoid this by batch-processing images only 5 by 5.
Of course, if you have dimensioned your server CPU/RAM to handle super high load, you could decide to raise this value to accelerate thumbnails generation (within acceptable limits for your hardware).
Managing Timeouts
Another important aspect of Cells Flows is that it can trigger long-running operations on your server, and sometimes it's not what you want. Or sometimes it is and you want to give a Flow some extra-time to make sure that it finished.
Timeouts are parameters that can be used at many levels of a Flow to precisely how each step should behave:
- Flow-level Timeout: a global limit applying to the entire Flow, will interrupt all running actions if it is reached.
- Queries Timeout: Populating objects based on specific criteria can be time-consuming if the result ends up loading a huge amount of objects. All selector types have a Timeout parameter to limit these queries.
- Actions Timeout: All actions also have a Timeout option to limit their processing-time.
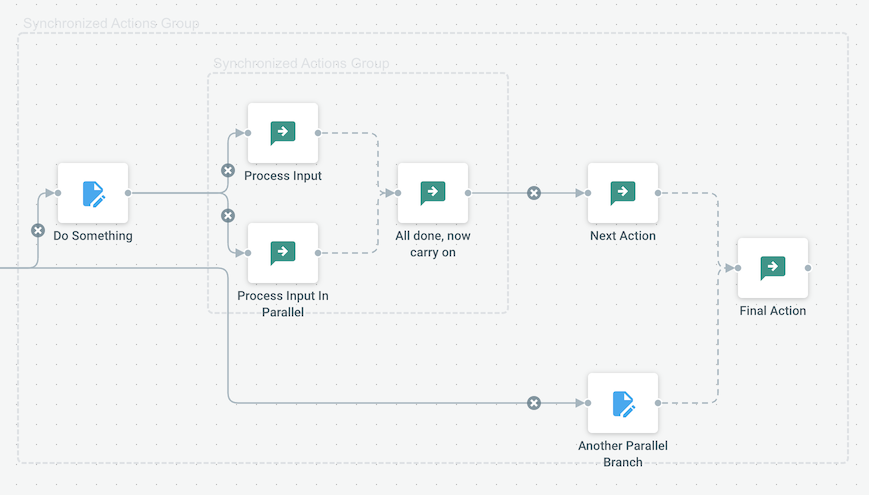
Synchronizing parallel tasks
Handling parallelism is useful for resource optimisation. But as soon as multiple branches are launched in parallel, they "forget" about their siblings, and they will finish "when they want". Generally this is not an issue, but in some case you want to actually :
- Launch many actions in parallel
- Wait that they are all finished
- Eventually collect and combine results from all these actions
- And finally do something specific or carry on with the flow.
This is in fact doable by setting a "Merge Action" on the output of an action : all branches that start from this action will be synchronized and re-combined into a unique message and the Merge Action will then be called.
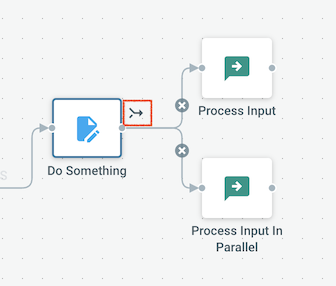
To create a merge action, look for the "branch" button on the output of the parent action that is dispatching parallel branches:
A simple example showing how two branches can be synchronized and merged back to carry on with other actions:
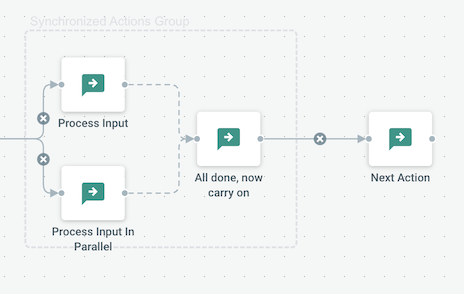
For those familiar with the Golang language, this is very similar to a sync.WaitGroup.
Some notes :
- A Merge Action can be set on the job trigger, and it will apply to all the job branches, allowing to set a final action, whatever the branches where.
- Due to technical limitations, one cannot add a Merge Action on an action that is already a Merge Action. If you need that, just chain another empty action and create the Merge Action on that one.
- Merges operations can be nested to regroup actions by clusters. See the image example below.