Dear Cells Users.
If you follow tech news, or any news for that matter, you’ve heard of ChatGPT, natural language processing (NLP) and generative AI. And you’ve also heard varying assessments of how NLP will affect the tech space and even everyday life. Since the first announcements, the development team at Pydio has been looking at the big picture of how Natural Language Processing could change how we work, share documents and collaborate.
We’re looking at things like:
- Automated taxonomy creation and document classification
- Smarter search based on content “semantics” (vs. word frequency)
- Content generation, like document summarization, Q&A creation, etc…
- Content processing, like feature extraction from documents
- Document authoring support and standardization
- Private information leak prevention (detecting credit card or personal data numbers)
- Platform security with automated log monitoring and anomaly detection
- And much more.
Every developer and product manager in the world is thrilled by the possibilities offered by ChatGPT (and all the LLM Generative AI APIs). Most vendors are doing their best to integrate NLP in one way or another into their products.
There’s Always a BUT
We’re just as excited. But we as developers, and by extension, you as users, need to be aware that these tools show impressive results because they are trained and run on massive data sets. And they are hosted by tech giants like Microsoft, Google or OpenAI.
So every time you send a prompt to Chat GPT or Bard or Bing with Chat GPT, you share both the information in your prompt and the result generated in the reply. If information privacy and data security are important to your organization, this should concern you.
Some of our competitors in self-hosted document sharing and collaboration have hurried to include API-driven NLP features in their products to bring exciting new functionality to their clients. Our perspective is that sending your sensitive information via API to third-party processors (whose stated aim is to know everything and leverage that knowledge) probably isn’t aligned with the priorities of organizations that choose to self-host their document sharing and collaboration.
We’re currently working with smaller, more efficient NLP models that can be self-hosted. This approach eliminates data security risks and allows for the development of specialized models that are a better fit for the challenges of document management, sharing and collaboration.
We want to provide you with the right tooling, both in terms of privacy (run your own model) and pricing (you need GPUs to process the data, so performance has to be optimized). Getting this all right will take a bit of time.
First Steps
For now, we are taking our first steps in NLP and rolling out new features that will improve user experience without putting your data at risk. Our first application is a smart assisted search function that suggests related search topics and helps users refine their search to find what they’re looking for more quickly.
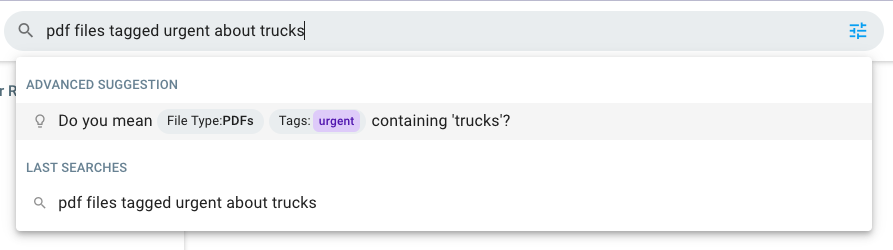
This new feature is already available for the English language in Cells 4.1.2. We’re working on self-hosted NLP models and a long list of NLP-powered features to help you boost productivity and usability, and ultimately elevate the document-sharing and collaboration experience.
Stay tuned for more AI-powered features coming soon!
Charles du Jeu
CEO Pydio


