File System Storage
Filesystem Datasource
The most standard driver you can use is actually the File System datasource: it has the huge advantage of storing the files directly on a local or network file system, thus on the other way round, to read any existing data stored in a file system and empower it with Pydio Cells capabilities.
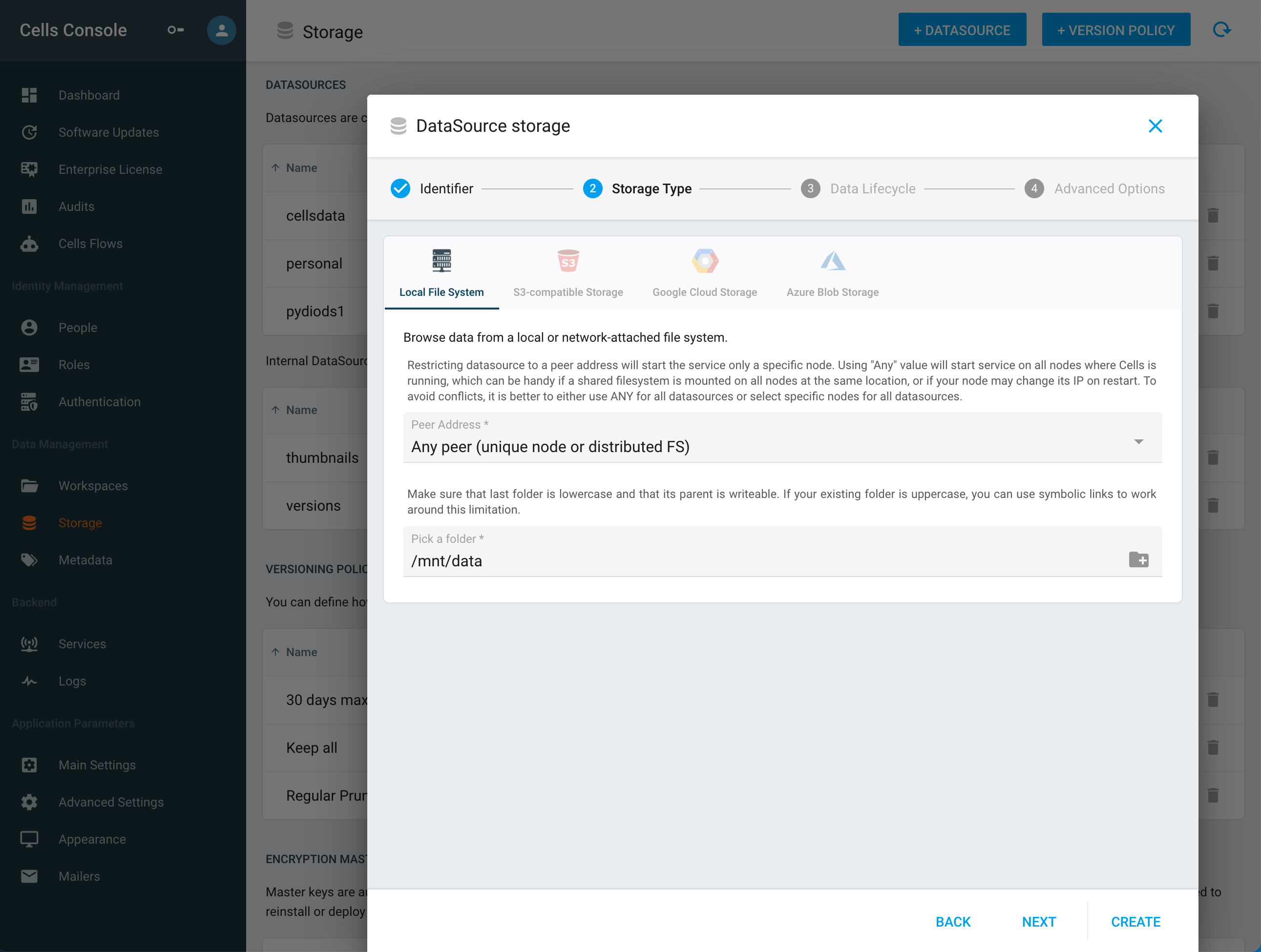
- Peer Address: address of the server where the storage is located. This is necessary for distributed setup where Pydio Cells may run on various machines. Active peers should be automatically detected and proposed in the list. (You can now choose the hostname which in case of an ip change will not disturb your datasource)
- Path: path to the directory on the server file system that is served as the root of this datasource.
- Storage is MacOS: if the Peer is running on MacOS, enable this to perform UTF8 names normalization, or you may see strange issues with names containing accented characters.
Warning when defining the path to the root folder of your datasource on the server, observe the following:
The path must be at least 2 levels down, for instance /mnt/data/
- The path must be absolute on the chosen peer: it must start from the root of the chosen server.
Once you have chosen a peer, note that the system automatically discovers the available directories and presents them in a popup list. - Due to the internal implementation of the file-system-based Object service (see previous chapter):
- The leaf folder is exposed as an Amazon S3 bucket, it must comply with the Bucket naming rules, which are the same as the DNS sub-domains naming rules: technical names that must be lower case and without spaces.
- The path must be at least two levels deep (defining e.g.
/tmpas a datasource does not work). - The user owning the process that starts the app (usually the
pydiouser) must have read and write permissions on this folder and on the parent folder.
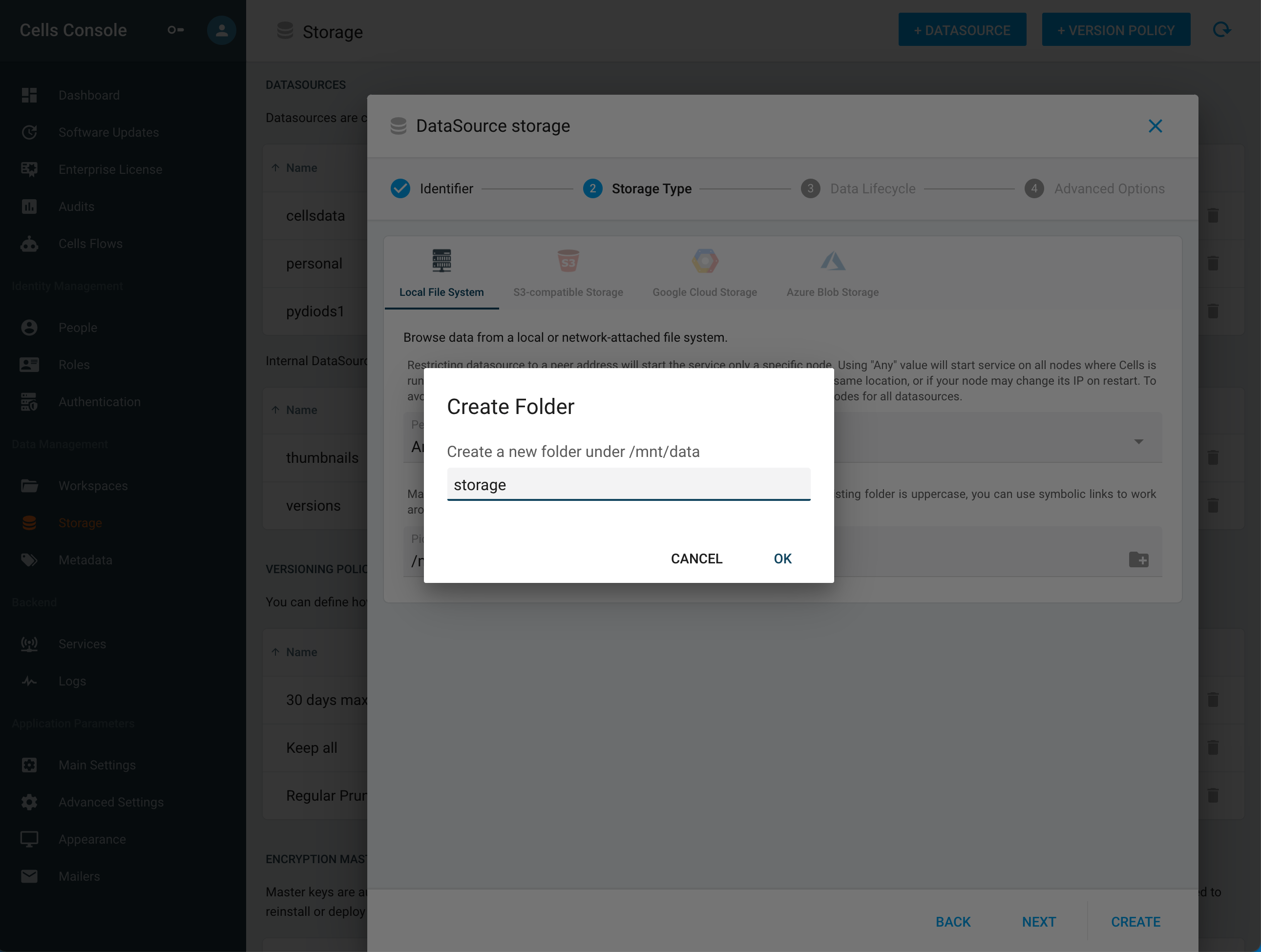
You can now create folders from the datasource menu, this feature will greatly enhance your productivity. Previously you had to first create your folder tree on the filesystem and then create a datasource that points to it, with the new workflow you can directly create your datasource and its tree.
You can notice the new button that allows you to use this feature.