Going Stateless
The rest of this section is a must-read to understand what you are doing when deploying Cells in cluster mode.
Deploying software in a distributed environment
A key to deploying software in a distributed environment is the ability to easily replicate a running instance of the software while being sure that any new clone will share data and communicate with existing ones:
- Providing high-availability is about ensuring that if a running node is broken, another one can easily take over.
- Providing horizontal scalability is about ensuring that if a running node is overloaded, one can easily add a new one and balance the load on it.
To achieve such flexibility, DevOps generally use pre-packaged software "images" (generally a virtual machine, or a container) that are isolated one from another in terms of CPU and memory, but working inside a private network to communicate with each other. It is crucial that these running images do not self-contain any business data that would be inacessible to any other instances.
Cells default setup limitation
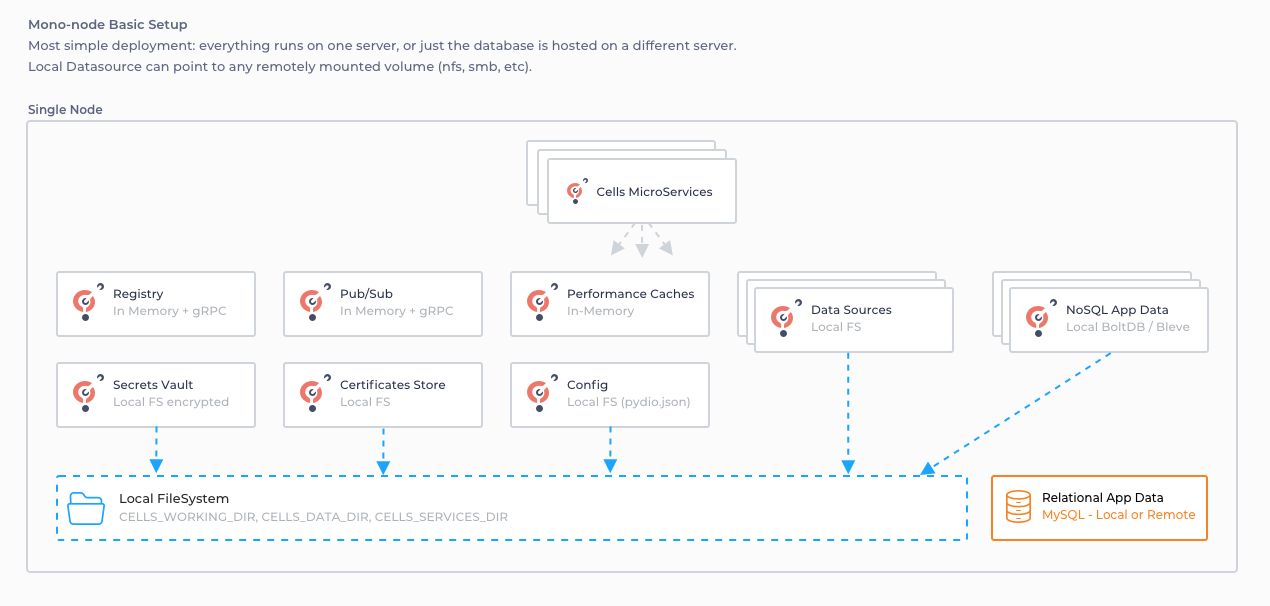
A standard standalone Cells setup uses multiple ways of storing data :
- Configuration, Vault configuration (JSON files)
- Logs, search indexes, activities, ... (BoltDB/BleveSearch files)
- Data tree, Permissions, Identity, ... (SQL)
- Cache, Service Registry, Pub / Sub events (in-memory)
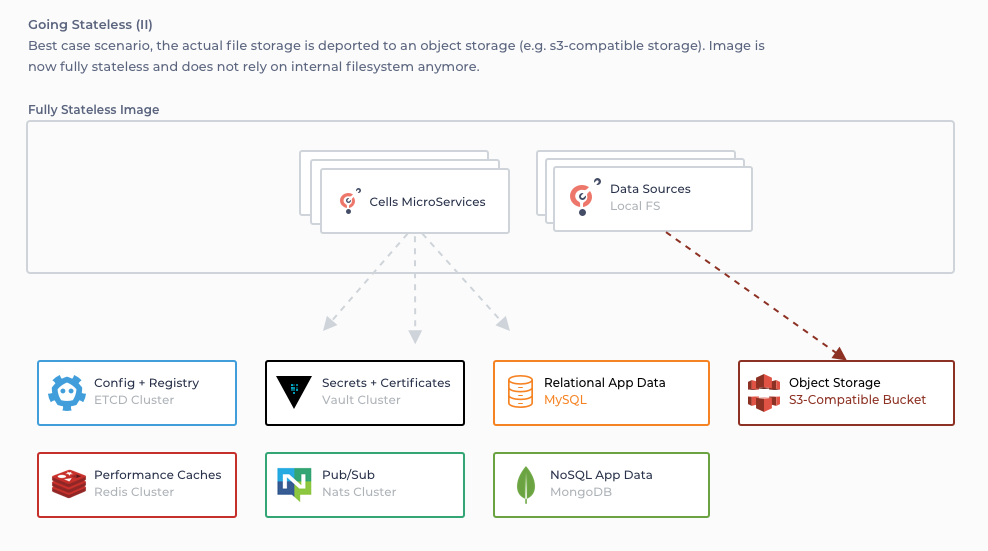
- Data (files, S3)
To have multiple Cells cooperate in multiple VMs in a network, we need to ensure that the same data is available simultaneously by each node without the possibility of it being corrupted. We can directly rule out a shared filesystem as it would not be reliable enough and would quickly lead to locking issues.
A Cells stateless deployment
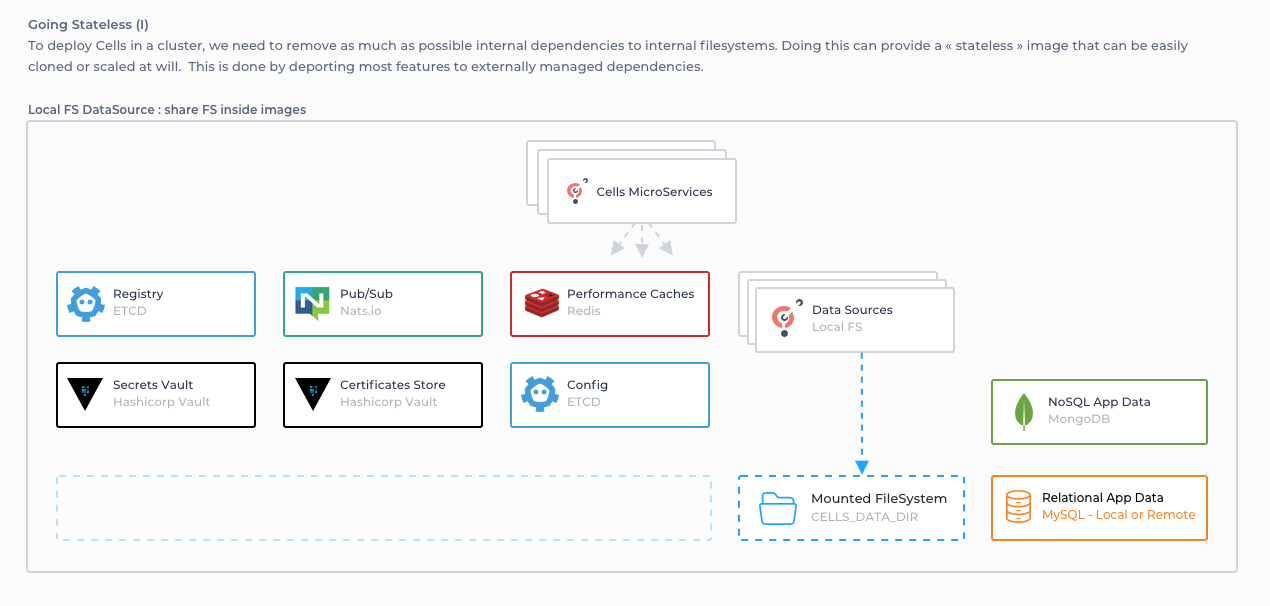
By plugging in new external storage drivers, we give Cells the flexibility to be accessible by all images safely and concurrently.
We chose external storage that can also be clustered so that each piece of the puzzle can achieve high availability and horizontal scalability individually :
- Configuration (JSON files, ETCD)
- Vault Configuration (JSON files, Hashicorp Vault)
- Logs, search indexes, activities, ... (BoltDB/BleveSearch files, MongoDB)
- Data tree, Permissions, Identity, ... (SQL)
- Cache (in-memory, Redis)
- Pub / Sub events (in-memory, Nats.io)
- Data (files, S3)
In a more concise view, we now have :