Tika Contents Extraction
Extract and index textual contents using Tika service.
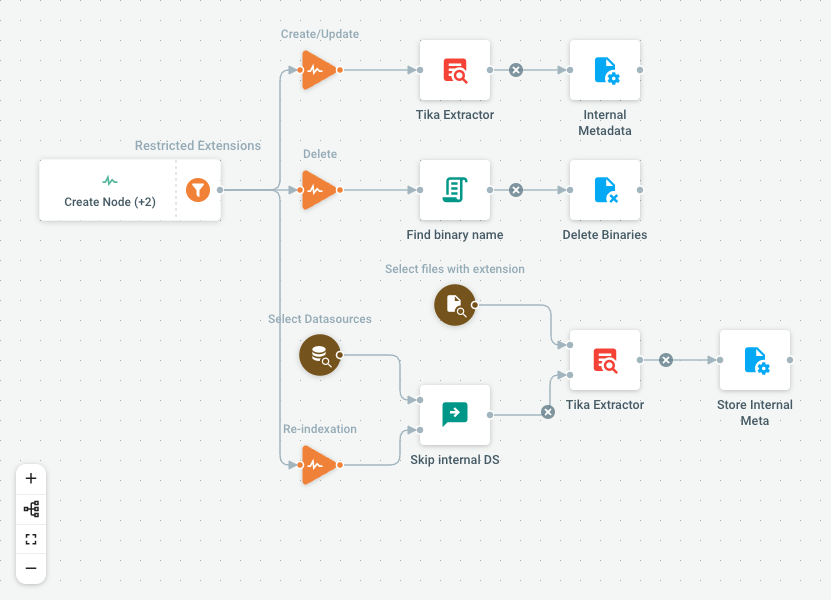
Apache Tika is an independent, open source, content extractor that supports a very wide range of file formats. It can even support OCR for extracting text from images. This flow sends file contents to Tika and gets the textual information to be indexed internally by the Cells search engine.
Install with Docker
Installing with Docker is as simple as running the following command:
docker run -d -p 9998:9998 apache/tika:latest
How It Works
The Flow assumes you have Tika running and available at a specific URL. Once extracted, the textual content is stored on Cells side to avoid having to resend file to Tika on re-indexation. The Flow is also in charge of cleaning associated metadata on file deletion, and can be triggered manually to re-extract contents from all compatible files (can be handy when first enabling job to run on existing files).
Tika provides also further metadata extraction, that can be indexed by Cells search engine as well.
Parameters
| Name | Type | Default | Mandatory | Description |
|---|---|---|---|---|
| TikaServer | text | localhost:9998 | true | TCP address for querying Tika server. |
| Extensions | text | pdf,doc,docx,html,xls,xlsx,pptx,key | false | List of extensions to be analyzed by Tika |
| ImagesExtensions | text | png,jpg,jpeg,bmp | false | If your tika instance supports OCR, submit these image formats as well. |
Trigger Type
Event-based
JSON Representation
{
"Label": "Tika Contents Extraction",
"Owner": "pydio.system.user",
"Metadata": {
"Description": "Extract and index textual contents using Tika service",
"Icon": "mdi mdi-magnify",
"TplCategory": "content-processing",
"Usage": "[Apache Tika](https://tika.apache.org/) is an independent, open source, content extractor that supports a very wide range of file formats. It can\neven support OCR for extracting text from images. This flow sends file contents to Tika and gets the textual information to be indexed internally by the Cells search engine.\n\n### How It Works\n\nThe Flow assumes you have Tika running and available at a specific URL. Once extracted, the textual content is stored on Cells side to avoid having to resend file to Tika on re-indexation. The Flow is also in charge of cleaning associated metadata on file deletion, and can be triggered manually to re-extract contents from all compatible files (can be handy when first enabling job to run on existing files).\n\nTika provides also further metadata extraction, that can be indexed by Cells search engine as well."
},
"Custom": true,
"EventNames": [
"NODE_CHANGE:0",
"NODE_CHANGE:3",
"NODE_CHANGE:5"
],
"Actions": [
{
"ID": "actions.contents.tika",
"TriggerFilter": {
"Label": "Create/Update",
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/jobs.TriggerFilterQuery",
"value": "Gg1OT0RFX0NIQU5HRTowGg1OT0RFX0NIQU5HRToz"
}
],
"Operation": 1
}
},
"Parameters": {
"additionalMeta": "Content-Type",
"compressContent": "true",
"extractContent": "pydio-binaries/tika-{{.Node.Uuid}}.gz",
"fieldname": "{\"@value\":\"Extension\"}",
"serverAddress": "{{.JobParameters.TikaServer}}"
},
"ChainedActions": [
{
"ID": "actions.tree.meta",
"Parameters": {
"metaJSON": "{}"
}
}
]
},
{
"ID": "actions.script.anko",
"Label": "Find binary name",
"TriggerFilter": {
"Label": "Delete",
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/jobs.TriggerFilterQuery",
"value": "Gg1OT0RFX0NIQU5HRTo1"
}
],
"Operation": 1
}
},
"Parameters": {
"script": "output = input\noutput.Nodes[0].Path = \"pydio-binaries/tika-\" + input.Nodes[0].Uuid + \".gz\""
},
"ChainedActions": [
{
"ID": "actions.tree.delete",
"Label": "Delete Binaries",
"Parameters": {
"fieldname": "{\"@value\":\"EventNames\"}",
"ignoreNonExisting": "true"
}
}
]
},
{
"ID": "actions.scheduler.log-input",
"Label": "Skip internal DS",
"DataSourceSelector": {
"Label": "Select Datasources",
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/object.DataSourceSingleQuery",
"value": "ag1jZWxsc0ludGVybmFsgAEB"
}
]
}
},
"TriggerFilter": {
"Label": "Re-indexation",
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/jobs.TriggerFilterQuery",
"value": "EAE="
},
{
"type_url": "type.googleapis.com/jobs.TriggerFilterQuery",
"value": "CAE="
}
]
}
},
"Parameters": {
"taskLogger": "true"
},
"ChainedActions": [
{
"ID": "actions.contents.tika",
"Label": "Tika Extractor",
"NodesSelector": {
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/tree.Query",
"value": "ChV7ey5EYXRhU291cmNlLk5hbWV9fS8wAVKSAXt7LkpvYlBhcmFtZXRlcnMuRXh0ZW5zaW9ucyB8IHJlcGxhY2UgIiwiICJ8In19e3tpZiAuSm9iUGFyYW1ldGVycy5JbWFnZXNFeHRlbnNpb25zfX18e3tlbmR9fXt7LkpvYlBhcmFtZXRlcnMuSW1hZ2VzRXh0ZW5zaW9ucyB8IHJlcGxhY2UgIiwiICJ8In19"
}
],
"Operation": 1
},
"Label": "Select files with extension"
},
"Parameters": {
"additionalMeta": "Content-Type",
"compressContent": "true",
"extractContent": "pydio-binaries/tika-{{.Node.Uuid}}.gz",
"fieldname": "{\"@value\":\"Extension\"}",
"serverAddress": "{{.JobParameters.TikaServer}}"
},
"ChainedActions": [
{
"ID": "actions.tree.meta",
"Label": "Store Internal Meta",
"Parameters": {
"metaJSON": "{}"
}
}
]
}
]
}
],
"MaxConcurrency": 10,
"NodeEventFilter": {
"Query": {
"SubQueries": [
{
"type_url": "type.googleapis.com/service.Query",
"value": "CiwKHnR5cGUuZ29vZ2xlYXBpcy5jb20vdHJlZS5RdWVyeRIKOgYucHlkaW9wARAB"
},
{
"type_url": "type.googleapis.com/service.Query",
"value": "CiQKHnR5cGUuZ29vZ2xlYXBpcy5jb20vdHJlZS5RdWVyeRICMAEQAQ=="
},
{
"type_url": "type.googleapis.com/tree.Query",
"value": "Um57ey5Kb2JQYXJhbWV0ZXJzLkV4dGVuc2lvbnN9fXt7aWYgLkpvYlBhcmFtZXRlcnMuSW1hZ2VzRXh0ZW5zaW9uc319LHt7ZW5kfX17ey5Kb2JQYXJhbWV0ZXJzLkltYWdlc0V4dGVuc2lvbnN9fQ=="
}
],
"Operation": 1
},
"Label": "Restricted Extensions",
"Description": "Keep only files, excluding .pydio hidden files"
},
"Parameters": [
{
"Name": "TikaServer",
"Description": "TCP address for querying Tika server.",
"Value": "localhost:9998",
"Mandatory": true,
"Type": "text"
},
{
"Name": "Extensions",
"Description": "List of extensions to be analyzed by Tika",
"Value": "pdf,doc,docx,html,xls,xlsx,pptx,key",
"Type": "text"
},
{
"Name": "ImagesExtensions",
"Description": "If your tika instance supports OCR, submit these image formats as well.",
"Value": "png,jpg,jpeg,bmp",
"Type": "text"
}
]
}